32-Bit Tiny GPU
A complete GPU stack built from scratch: custom 32-bit ISA, 12-module SystemVerilog RTL, C-based assembler (AXEL), and a neural network that trains end-to-end on simulated hardware.
Project Overview
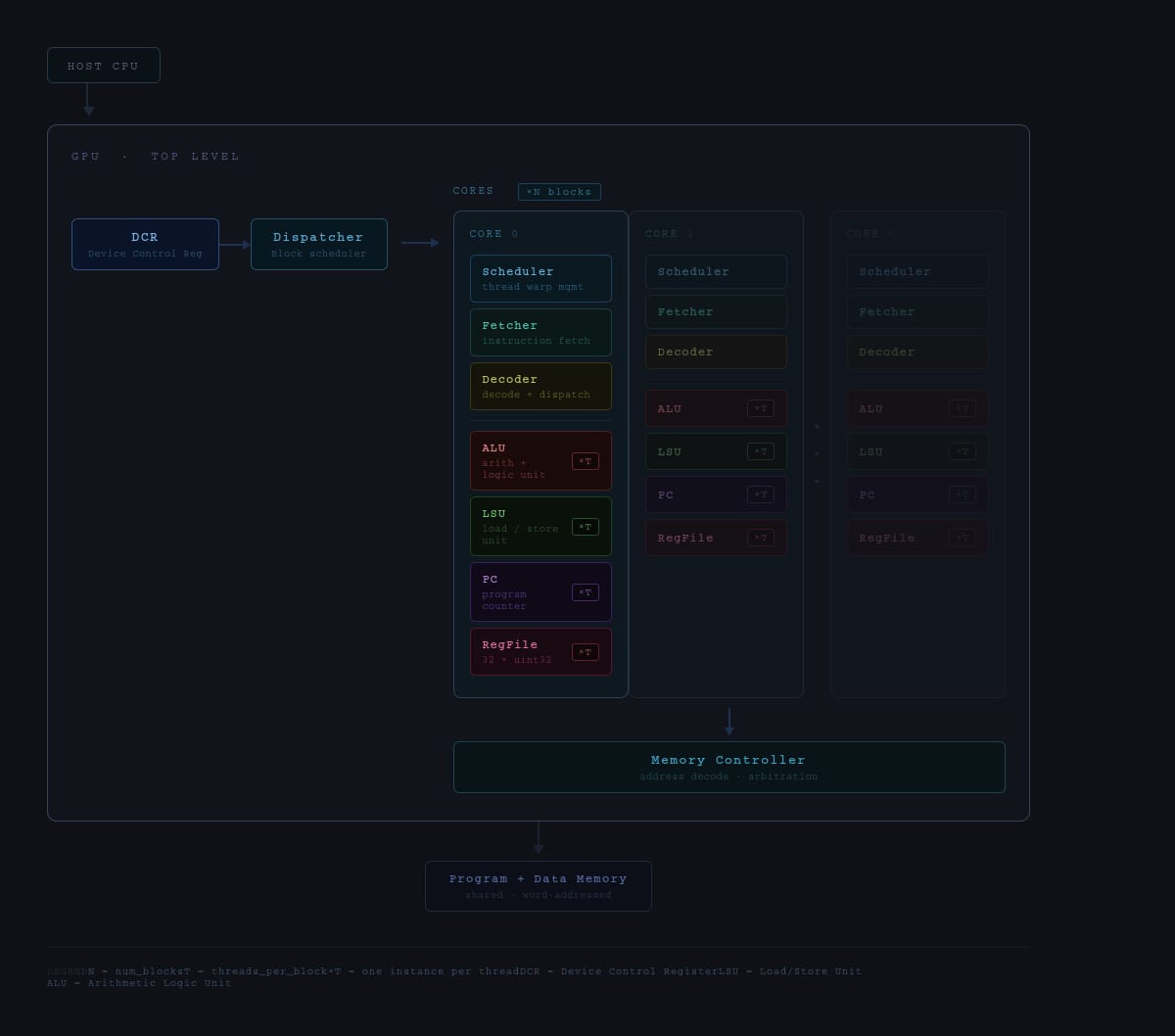
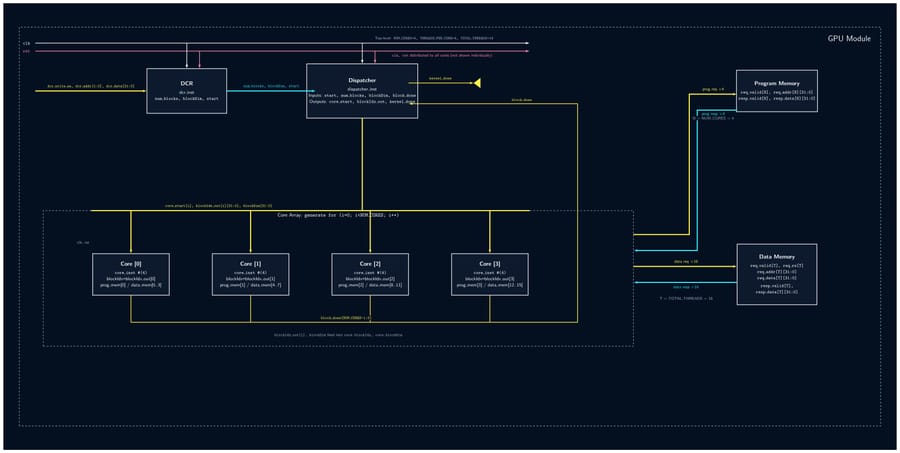
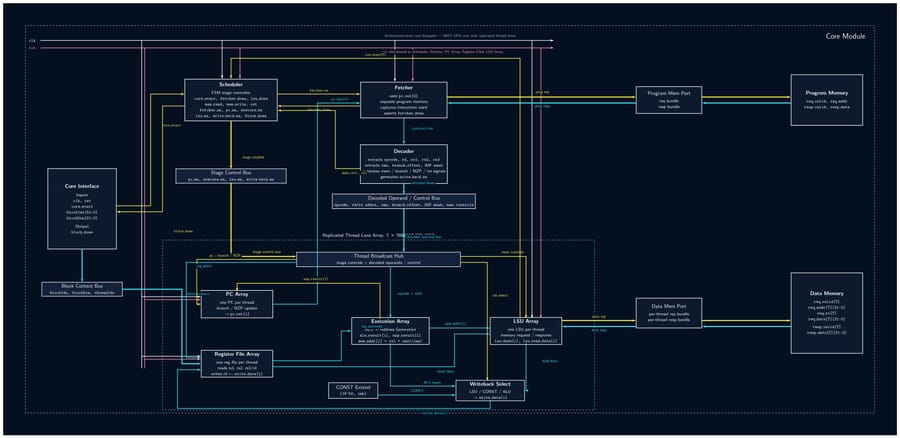
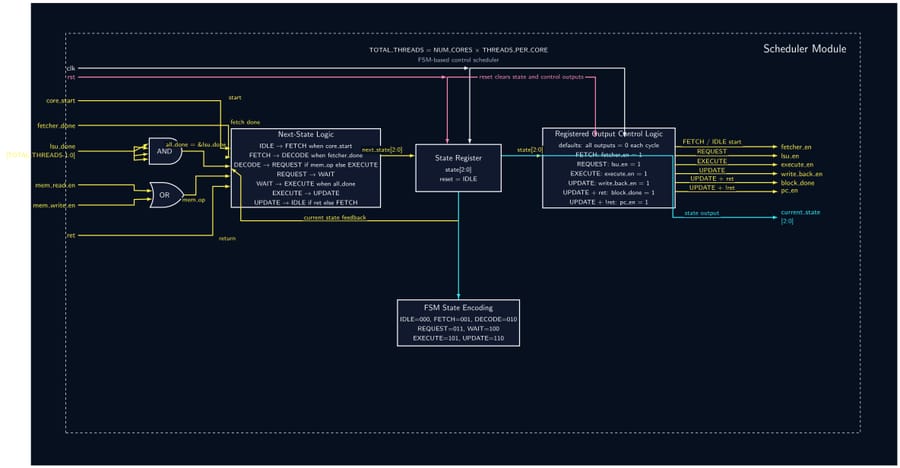
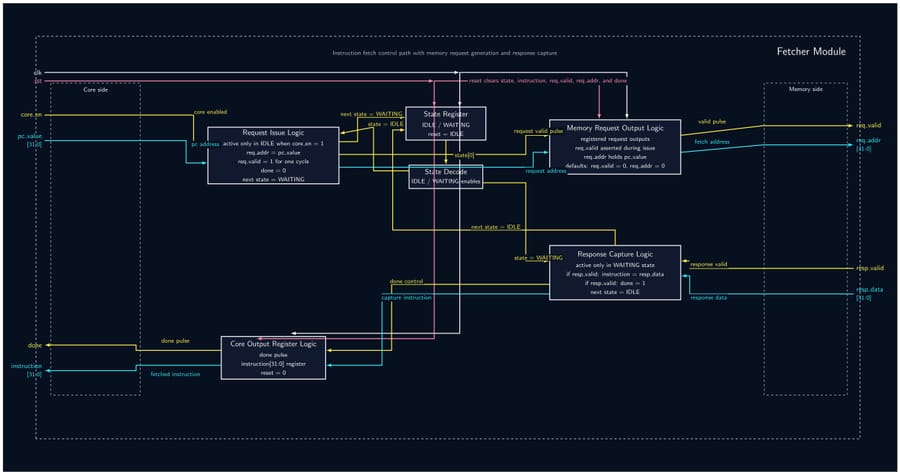
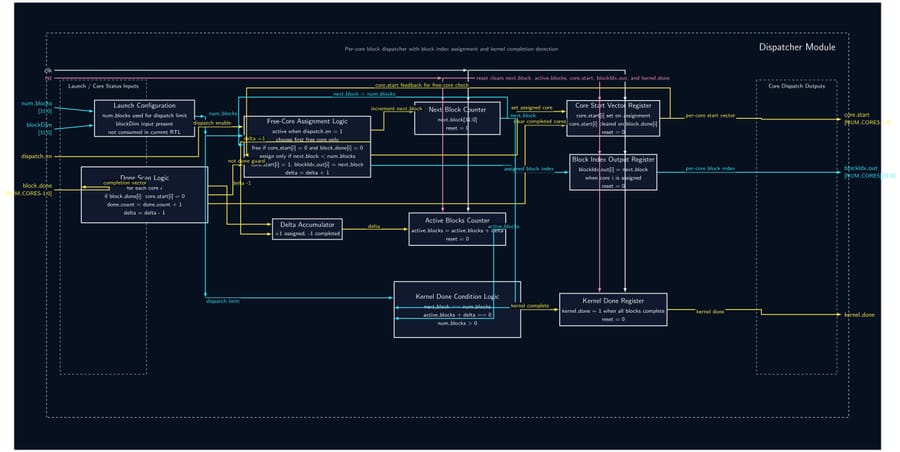
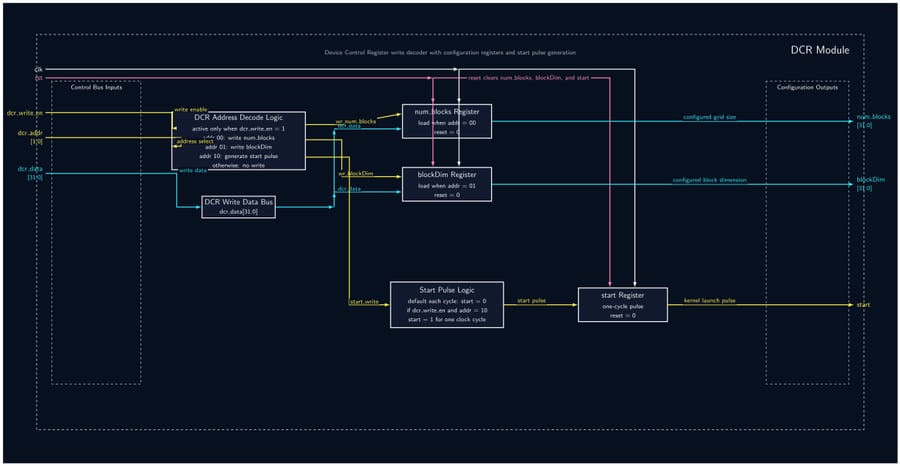
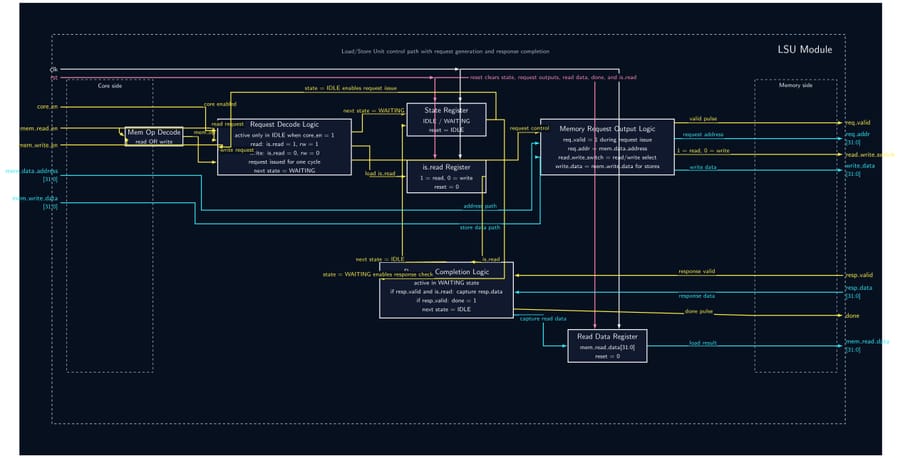
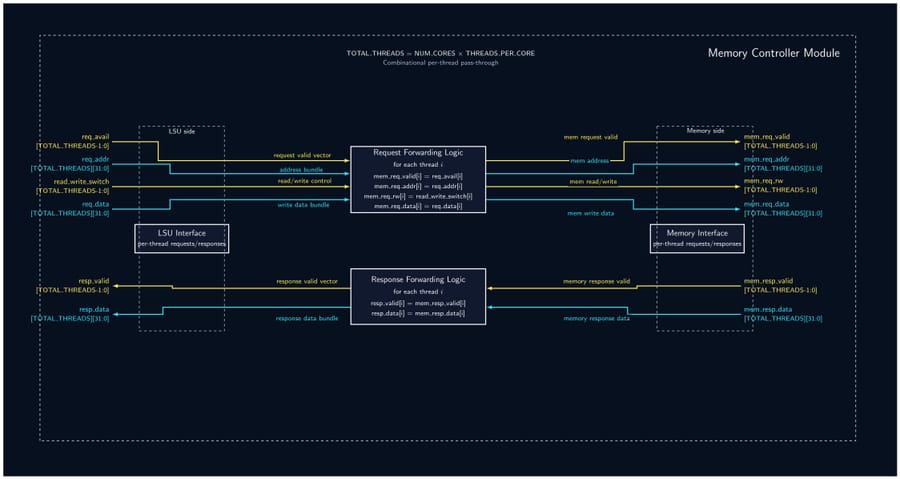
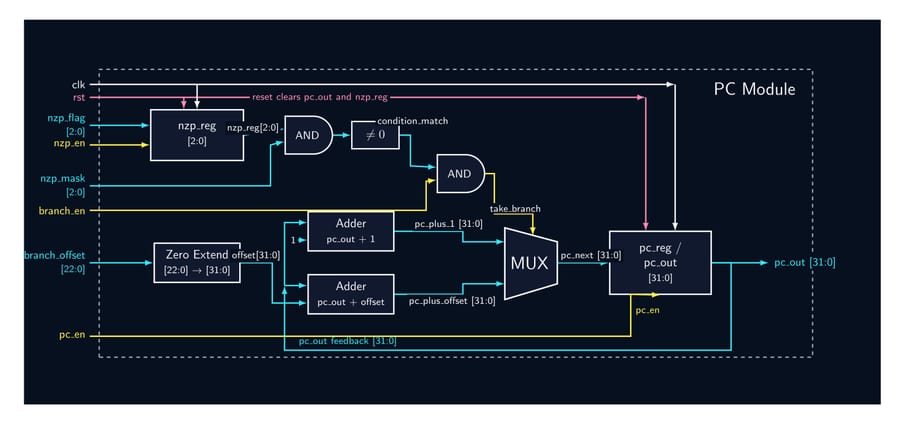
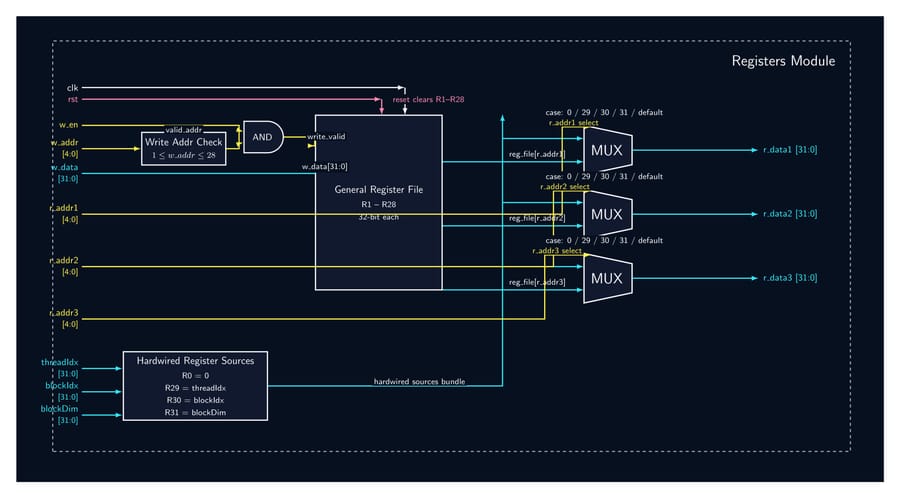
32-Bit Tiny GPU is a ground-up implementation of a programmable GPU — from the silicon-level RTL all the way to a working assembler and a neural network that trains and infers on the simulated hardware. The architecture features a custom 21-instruction 32-bit ISA, a seven-state pipeline scheduler, and a configurable multi-core SIMD execution model (default: 4 cores × 4 threads = 16 concurrent threads). A Host CPU feeds kernel programs and data into a Device Control Register (DCR), which a Dispatcher then breaks into thread blocks and assigns to individual cores. Each core runs a full pipeline: Scheduler → Fetcher → Decoder → ALU/LSU → PC, with the register file holding 32 × uint32 words per thread. A shared Memory Controller arbitrates all core memory requests down to a unified Program + Data Memory. On the software side, a C-library assembler called AXEL compiles kernel source into .hex files that drive the simulation. The project culminates in a Q8 fixed-point neural network — a 4×4 linear layer with branchless ReLU — that trains over 20 epochs entirely on the simulated GPU, converging within 2.5% of the target output with learned weights that persist between runs.
Objectives
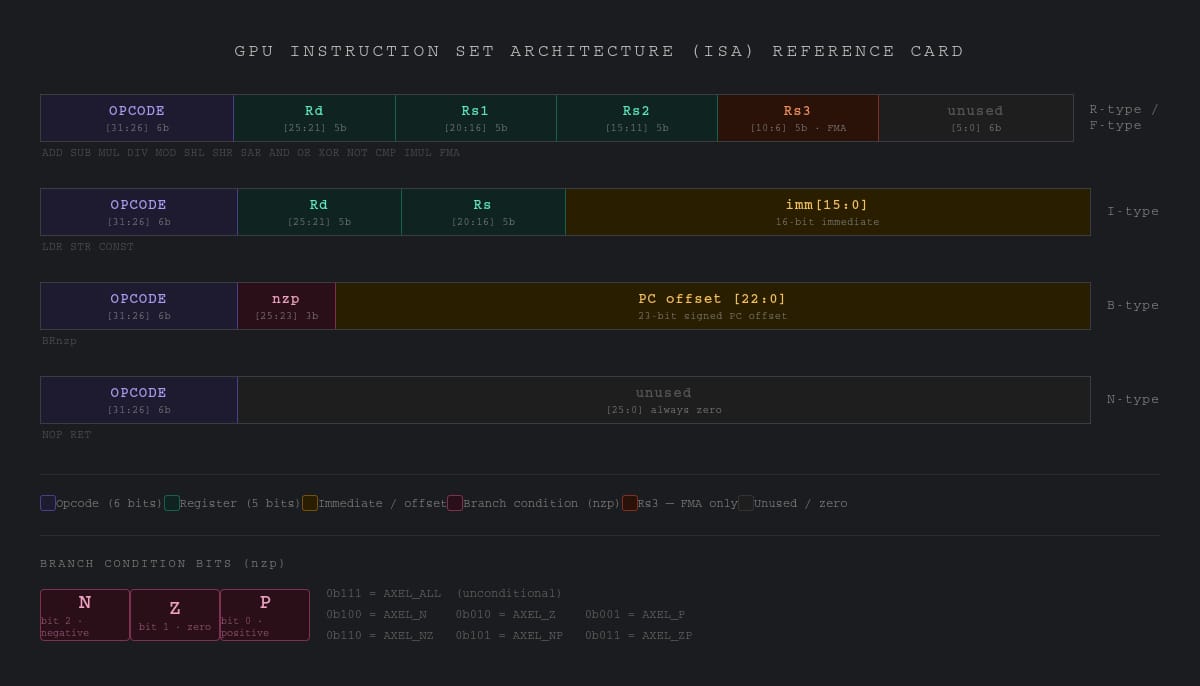
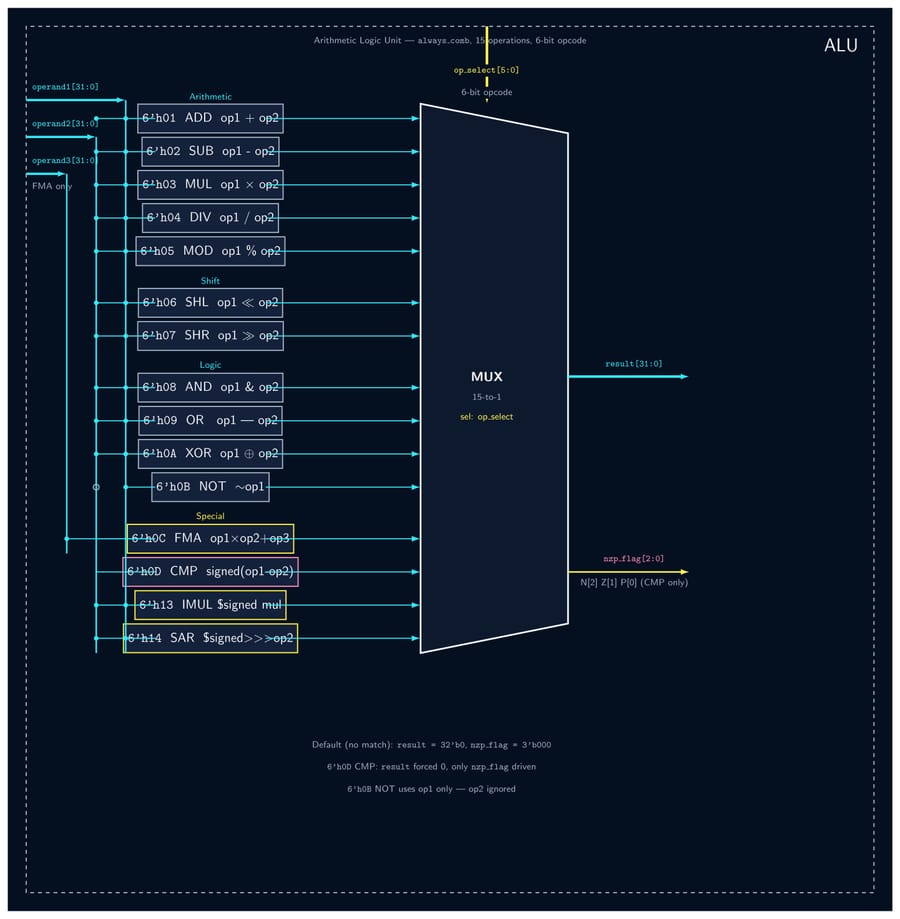
- Design a minimal but Turing-complete 32-bit GPU ISA covering arithmetic, logical, memory, branching, and SIMD-critical signed operations across 4 instruction encoding formats
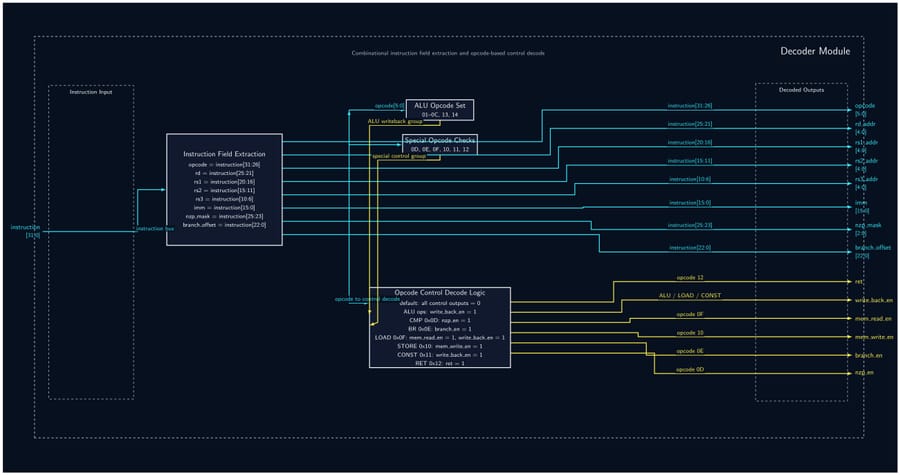
- Implement all 12 RTL modules (DCR, Dispatcher, Scheduler, Fetcher, Decoder, ALU, LSU, PC, RegFile, Memory Controller, Core, Top-Level GPU) as fully parameterized SystemVerilog — no hardcoded constants
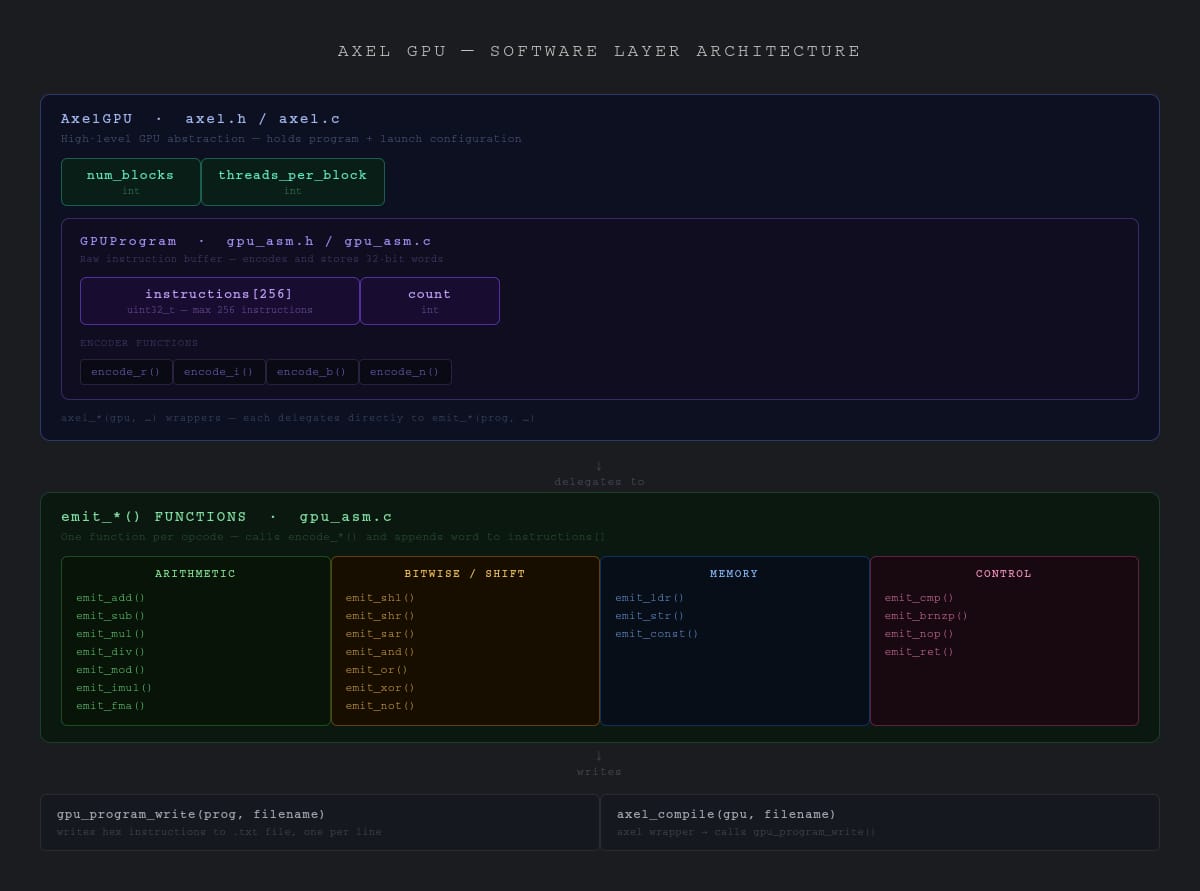
- Build AXEL, a C-library assembler that parses GPU assembly source and emits .hex kernel files directly consumable by the Icarus Verilog simulation
- Demonstrate five progressively complex kernel programs — from a minimal add kernel to a complete neural network training loop — to validate each pipeline stage
- Train a 4×4 linear + ReLU neural network with Q8 fixed-point gradient descent entirely on the GPU simulation, proving end-to-end ML workload viability on custom silicon
- Achieve 100% unit-test pass rate across all 12 individual RTL modules and a passing top-level integration test under cocotb and Icarus Verilog
- Prepare an FPGA port targeting Xilinx/Lattice devices with a combined flat Verilog and constraint file ready for synthesis
Project Details
Status
Completed Phase 1 (RTL, Simulation & GDSII) — FPGA Port in ProgressDuration
March 2026 - Present
Category
VLSI & Computer Architecture
Repositories
Project Gallery